Stanford CS234: Reinforcement Learning | Winter 2019 | Lecture 2
Given the model of the world

Markov Property → stochastic process evolving over time(whether or not I investi stocks, stock market changes)
Markov Chain
- sequence of random states with Markov property
- no rewards, no actions
Let
for finite number(
example discussed last section(we abort discussion of rewards and actions for easy understanding)
at state
Let’s say we start at
Markov Reward Process(MRP)
- Markov Chain + rewards
- no actions
for finite number(
Horizon
- number of time steps in each episode
- can be either finite or infinite
Return(
- Discounted sum of rewards from time step t to horizon
State Value Function(V(s))
- ‘Expected’ return from starting in state
if the process is deterministic Return = State Value → since there would be single identical route .
Example
return value for sample episode, where
episode
Computing the Value of Markov Reward Process
- can estimate by mathematical simulation
- MRP value function satisfies
- Proof
Matrix form of Bellman Equation for MRP
- analytic method of calculation
for finite MRP, we know
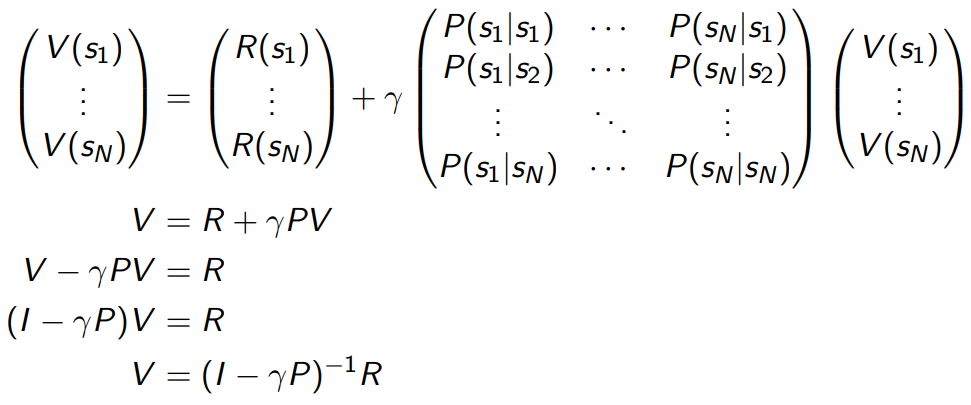
Iterative Algorithm for Computing Value of a MRP
Dynamic Programming
- Initialize
for k = 1 until convergence
for all
** computational complexity is simpler compared to analytical method
Markov Decision Process(MDP)
- Markov Reward Process + actions
for finite number(
MDP is a tuple: (
Example

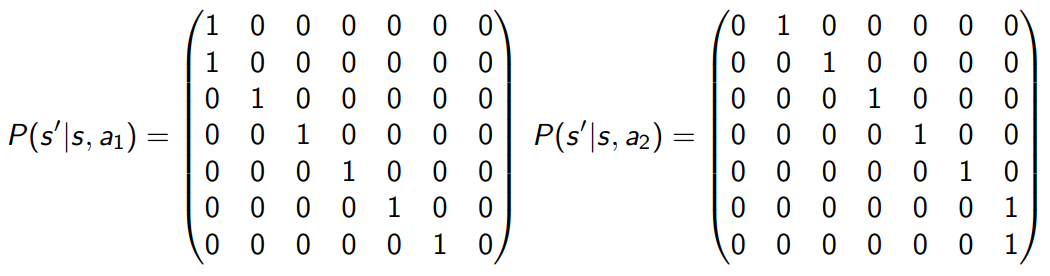

action

MDP policies can be either *deterministic(I always do this in this state) or stochastic(there exists set of possible actions for this state)*
Markov Decision Process
- MDP +
MDP Policy Evaluation - Iterative Algorithm
- Initialize
for k = 1 until convergence
for all
this is a Bellman backup for particular policy
Example

!

only two actions
compute iterations!
since
Practice
- Dynamics :
- Let
Find
— — — — — — — — — — — — — — — — — — — — — — — — — — —
$$
V^\pi_2(s_6)=0 + 0.5(0.50+0.510)=2.5
$$
MDP Control
- compute optimal policy
- there exists a unique optimal value function
- Optimal policy for an infinite horizon MDP→ Stationary (in same state, time stamp doesn’t matter)
- → not necessarily unique since there may exist other state-action with same optimal value
- → Deterministic
* optimal policy is not unique whereas an optimal value function is unique
Question


MDP Policy Iteration(PI)
for infinite horizon,

State-Action Value
immediate reward + expected reward starting from next state, following
Policy Improvement(steps)
- compute all
- compute new
$\pi_{i+1}$ is either $\pi_i$ or a different $a$ that maximized $Q$ value thus“if we took a new policy for an action and then follow
Monotonic Improvement in Policy Value
the new policy is greater than equal to the old policy for all states
Proposition :
- Proof


MDP Value Iteration (VI)
- Know optimal value and policy but only gets to act for
Bellman Equation and Bellman Backup Operators
Bellman Equation → Value fucntion of a policy must satisfy
Bellman backup operator
- applied to a value function and return a new value function
- yields a value function over all states
Policy Iteration as Bellman Operations
- Bellman backup operator
- repeatedly apply operator until
Value Iteration(VI)

Contraction Operator
- Let
- if
- → the distance between two vectors can shrink applying certain operator
Question : Will Value Iteration Converge?
A : Yes, because Bellman backup is a contraction operator
- Proof

참고할 링크
'ML Study > Stanford CS234: Reinforcement Learning' 카테고리의 다른 글
| Stanford CS234 Lecture 6 (0) | 2022.08.09 |
|---|---|
| Stanford CS234 Lecture 5 (0) | 2022.08.08 |
| Stanford CS234 Lecture 4 (0) | 2022.08.05 |
| Stanford CS234 Lecture 3 (0) | 2022.08.05 |
| Stanford CS234 Lecture 1 (2) | 2022.08.04 |




댓글