일단 들어가기 앞서 해당 논문은 이전에 포스팅한 PerAct의 후속 논문이다. 그거 읽고 와야 이해가 편하다!
https://maltese-rocks.tistory.com/63
PerAct 논문 리뷰(PERCEIVER-ACTOR: A Multi-Task Transformer for Robotic Manipulation)
PERCEIVER-ACTOR: A Multi-Task Transformer for Robotic ManipulationPerceiver-Actor: A Multi-Task Transformer for Robotic Manipulation기본적으로 알면 이해에 도움이 되는 TransformerAttention Is All You Need💡 **Keywords:** Transformers, Langu
maltese-rocks.tistory.com
GNFactor: Multi-Task Real Robot Learning with Generalizable Neural Feature Fields
GNFactor: Multi-Task Real Robot Learning with Generalizable Neural...
GNFactor: Multi-Task Real Robot Learning with Generalizable Neural Feature Fields
It is a long-standing problem in robotics to develop agents capable of executing diverse manipulation tasks from visual observations in unstructured real-world environments. To achieve this goal, the robot needs to have a comprehensive understanding of the
arxiv.org
💡 Keywords: Robotic Manipulation, Neural Radiance Field, Behavior Cloning
Introduction
적은 양의 demonstration으로 Imitation learning을 통한 multi-task manipulation을 구현한다.
현재까지의 로봇 러닝 분야의 visual representation은 2D 이미지에 중점을 두었으나 이 경우 pre-trained 모델에서 representation을 찾아와 policy gradient와 함께 optimize한다. 보다 복잡한 task를 수행하기 위해 3D visual representation을 활용하는 방법이 연구되고 있으며 NeRF를 이용한 3D scene representation으로 지도학습을 진행한 경우가 있다.
본 연구에서는
a language-conditioned policy using a novel representation leveraging both 3D and semantic information for multi-task manipulation
를 소개한다.
Pre-trained 2D 모델의 semantic feature를 NeRF를 통과시켜 General Neural Feature Field(GNF)를 학습시키고 이를 기반으로 policy 학습을 통해 GNFactor를 개발한다.
학습 과정은 두 가지로 갈린다.
- GNF training
- Expert demonstration을 바탕으로 view synthesis와 volumetric rendering을 활용해 GNF를 학습시킨다. Volumetric rendering에서 RGB 픽셀 렌더링 외에도 모델 feature을 함께 렌더링하며, GNF는 픽셀과 feature를 동시에 학습한다.
- GNFactor joint training
- GNF의 학습 목표로 최적화된 3D volumetric feature을 기반으로 BC를 수행하여 전체 모델을 end-to-end로 학습
Related Work
기본적으로 NeRF와 PerAct를 알면 이해하기 쉽다.
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-con
arxiv.org
Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation
Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation
Transformers have revolutionized vision and natural language processing with their ability to scale with large datasets. But in robotic manipulation, data is both limited and expensive. Can manipulation still benefit from Transformers with the right proble
arxiv.org
Learning Generalizable Feature Fields for Mobile Manipulation
Learning Generalizable Feature Fields for Mobile Manipulation
An open problem in mobile manipulation is how to represent objects and scenes in a unified manner, so that robots can use it both for navigating in the environment and manipulating objects. The latter requires capturing intricate geometry while understandi
arxiv.org
Method
GNFactor를 한 문장으로 소개하면 다음과 같다.
a multi-task agent with a 3D volumetric representation for real-world robotic manipulation
GNFactor는 동일한 volumetric representation을 공유하는 volumetric rendering module과 3D policy module로 구성된다.
volumetric rendering module(Fig3 중앙)은 카메라 데이터에서 RGB 이미지를 재구성하고 vision-launguage model(e.g. Stable Diffusion)의 임베딩을 처리하도록 GNF를 학습한다.
task와 관계없이 사용 가능한 vision-language model의 특성이 volumetric representation의 일반적인 feature을 뉴럴 렌더링을 가능케 하여 3D policy module의 학습을 돕는다. language는 CLIP인코더 사용

Problem Definition
한 대의 RGB-D 카메라(front) 이미지로 만든 3D voxel space ∈ $R^{100^3*3}$ 크기의 observation space 와 일부 RGB 카메라(시뮬은 19, 실제는 2대)를 이용해 GNF를 학습한다.
Action : translation[3], rotation[3], gripper_openness[2(0,1)], collision_avoidance[2(0,1)]
이 연구에서도 keyframe을 사용한다! keyframe 설정 후 behavior cloning의 형태로 굴러간다.
Learning
Fig. 3을 보며 이해하기 편하다.
RGB-D 이미지를 100^3 크기의 voxel로 변환한 후 3D voxel encoder 통과시켜 volumetric representation $v ∈ R^{100^3*128}$ 형태로 출력한다. volumetric representation의 형태와 language align을 위해 $v$ 를 받아 (1)2D 이미지를 재생성하고 (2)2D vison-language 모델의 예측값을 활용하여GNF를 학습한다.
Generalizable Neural Feature Fields
GNF는 세 가지 함수로 구성된다.
(1) density function $\sigma(x,v_x):R^{3+128}→R_+$ : 3D point와 3D feature → density
(2) RGB function $c(x,d,v_x):R^{3+3_128}→R^3$ : 3D point, 3D feature, direction → color
(3) vision-language embedding $f(x,d,v_x):R^{3|3|128}→R^{512}$ : 3D point, 3D feature, direction → vision-language embedding

전체를 조합한 Loss는 아래와 같이 나온다.

학습을 위해 NeRF의 계층구조와 depth-guided sampling을 적용한다.
Action Prediction
volumetric representation의 최적화는 GNF 모듈만이 아니라 3D policy에서의 task에 대한 action 예측을 위해 필수적이다.
PerAct처럼 Perceiver Transformer를 사용해 고차원의 멀티모달 입력(3D volumetric rep)을 처리한다.
Perceiver (PerAct 리뷰에서 발췌)
Input: RGB-D voxel grid & language goals.
*language goal*은 pretrained된 CLIP의 language encoder를 그대로 사용, 이를 이용해 language를 unseen semantic categories와 instance에 대해 align
*voxel observation*은 ViT처럼 5^3 사이즈의 3D patch로 분리되고 flatten된다.language encoding은 linear layer로 미세 조정되어 voxel encoding과 결합되어 input 시퀀스를 구성. 이후, voxel과 토큰의 위치를 통합하기 위해 "학습된" positional embedding이 추가.
Structure: Perceiver Transformer를 사용해 large input spaces를 a small set of latent vectors로 인코딩
Process: voxel grid를 3D patche로 쪼개고 3D convolution layer를 통과해 인코딩한다. 인코딩된 latent vector와 language feature 결합하여 Perceiver Transformer 통과.
Output: 이 시퀀스는 다시 원래 보컬 크기로 업샘플링 되어 3D Q-functions을 통해 행동 값 예측

Perceiver는 전체 input을 직접 처리하는 대신, cross-attention을 통해 input과 latent vector를 결합하여 연산을 수행. 그 다음, self-attention을 통해 인코딩을 반복적으로 수행하며, 최종적으로 생성된 latent vector를 다시 cross-attention을 통해 원래 input과 동일한 차원으로 디코딩한다.
Perceiver는 6개의 self-attention layer와 input, output에 각각 하나의 cross-attention layer를 사용한다. 디코더는 input의 정보를 어느 정도 유지하기 위해 UNet과 유사하게 skip connection을 사용한다. voxel grid를 3D Q-function으로 형성하여 translation, rotation, gripper_open_state, collision avoidance의 Q값을 구한다.
학습 과정의 Loss이다.
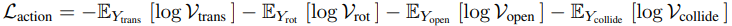
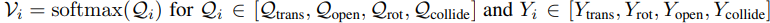
Optimization
전체 모델은 위 GNF에서 구한 Loss에 weight을 곱하여 전체 Loss를 계산하고 이를 최소화하는 방향으로 간다.
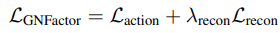
Results
유사한 language-conditioned multi-task agent PerAct와 성능 비교
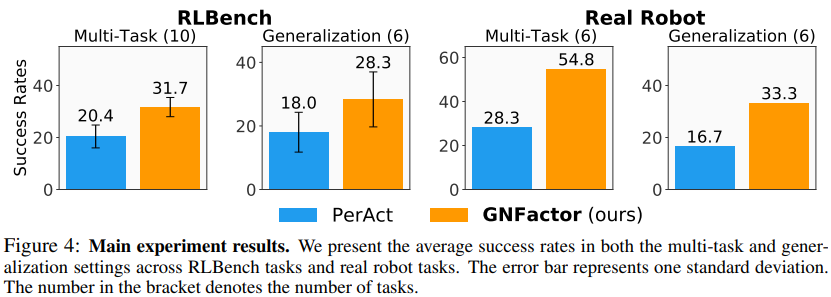
Simulation
전체적으로 multi-task, generalization 면에서 PerAct보다 우수하다고 주장한다.
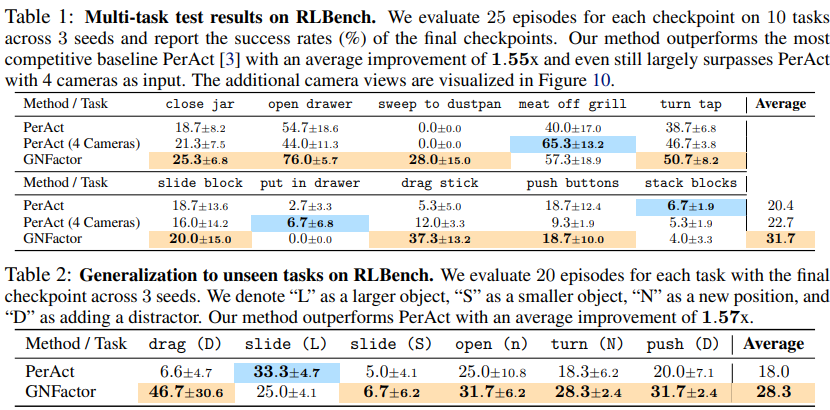
Ablation test는 PerAct에서와 크게 다르지 않게 진행한다. Skip connection은 마찬가지로 rendering과정에서 원본이 유실되는 것을 방지해주는 역할을 하는 것으로 보인다. rendering loss와 reconstruction loss의 compensation이 아주 중요하다.

GNFactor는 reconstruction loss와 action loss 를 동시에 최적화 하기에 GNF 단독으로 학습한 것보다는 낮은 성능을 보인다. 실제 환경에서는 카메라 데이터가 부족하고 RGB-D 한 기의 데이터가 부정확해서 precise한 reconstruction 보다는 의미적 해석을 중심으로 한다.
Real Robot
HW : xArm7
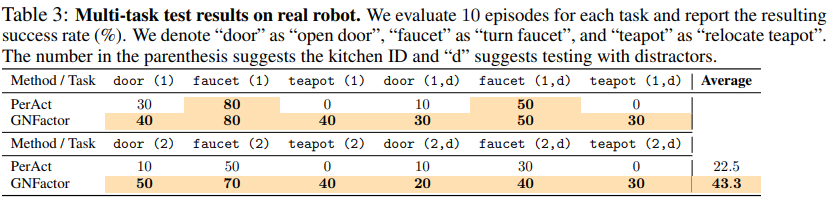
대부분의 경우 GNFactor가 PerAct 보다 성능이 좋다!
Limitation
GNFactor의 가장 큰 한계는 GNF학습을 위한 다양한 카메라 뷰의 필요성이다. 현재 통 3대(시뮬은 20대)의 카메라를 사용하기에 real world scaling이 어려울 것으로 보인다.




댓글